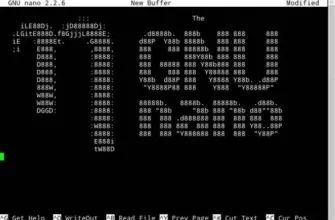
Uniq is designed to search for identical strings in the arrays of the text. Thus with the found matches, the user can perform many actions — for example, remove them from the output or Vice versa, to deduce only them.
The work of the team is done with text files (including recordings of scripts) and with the text printed in the command line terminal.
Syntax uniq
The command is as follows:
$ uniq options filhistorik filmless
The source file specifies where it is necessary to read the data, and a file for writing – where to write the result. But they are not required. In the examples we will type the text that needs editing, directly in the command line terminal using another command — echo, and applying to it the option -e. It will look like this:
echo -e [text, words separated escape sequencen] | uniq
This sequence is necessary to indicate the utility that each word appears on a new line. If you specify only the name of the source file, the command will appear directly in the terminal window. And if you have the output file, the text will be printed in the body of the document.
Options the uniq
The uniq has the following main options:
- -u (–unique) — outputs only those rows that have no duplicates.
- -d (–repeated) — if a line is repeated several times, it will be displayed only once.
- -D — displays only duplicate rows.
- –all-repeated[=METHOD] same as-D, but when using this option between the groups of identical rows in the output will display an empty string. [=METHOD] can be one of three values — none (default), separate , or prepend.
- –group[=METHOD] — removes all text, thus dividing the group of strings an empty string. [=METHOD] has the value of separate (default), prepend, append , and both, among which the need to choose one.
Along with the basic options can be additional. They are needed for the more subtle settings of the command:
- -f (–skip-fields=N) — is a comparison of the fields beginning with the number that follows after this is the letter N. the Field is a word, though, to call them words in a literal sense is impossible, because the word team considers any sequence of characters, separated from other sequences by a space or by tabs.
- -i (–ignore-case) — the comparison would have value in the case in which the printed characters (uppercase and lowercase letters).
- -s (–skip-chars=N) — works like -f, however, ignores a certain number of characters, not strings.
- -c (–count) — at the beginning of each row displays a number that indicates the number of repetitions.
- -z (–zero-terminated) — instead of a newline when output is used as the string delimiter NULL.
- -w (–check-chars=N) — an indication that you need to compare only the first N characters in strings.
Examples of the use of uniq
First of all, it should be noted the main feature of uniq — it compares only strings that are close. That is, if the two strings consisting of identical sets of symbols are consecutive, they will be discovered, and if between them there is a string with a different set of characters — it will not be so before the comparison it is desirable to sort the rows using sort. Without the use of files uniq works like this:
echo -e heavenpablaka ofpoblacipablaka ofSolnceof zvezdy | uniq
After uniq, you can use its options. Here is some example output, where not simply removed the repetition, but also indicate the number of identical rows:
echo -e heavenpablaka ofpoblacipablaka ofSolnceof zvezdy | uniq -c

Now apply the command to text, which is in the file.
uniq --all-repeated=prepend text-example.txt

As you can see, looking at the screen, the team brought in as a duplicate, only the second and third group of rows.

The reason for this is invisible whitespace, which is at the end of one of the rows of the first group. You need to be very careful when using uniq to get a quality result.
Used the option –all-repeated=prepend did its job of adding blank lines at the beginning, the end and between groups of lines. Now let’s compare only first 5 characters in each line.
echo -e sky slashed by lightningof poblaci in the skypablaka dispersed windpablaka of blocked out the sunSolnce shines brightof zvezdy seem huge | uniq-w5

As you can see in the screenshot, the duplicate rows that begin with the word “clouds” have been removed. There was only the first of them. Output only unique lines using-u option looks like this:
echo -e heavenpablaka ofpoblacipablaka ofSolnceof zvezdy | uniq -u

To ignore a certain number of characters at the beginning of the same row, use the option –skip-chars. In this case, the team will miss the word “cloud”, comparing the word “pinnate” and “white”.
echo -e skiesof pablaka Cirrusof pablaka Cirrusof pablaka whiteSolnceof zvezdy | uniq --skip-chars=6

And here is a good demonstration of the differences when using the option –group with different values. both added a blank line before the text and after it, as well as between groups of rows.
echo -e heavenpablaka ofpoblacipablaka ofSolnceof zvezdy | uniq --group=both

While append not add a blank line before the text:
echo -e heavenpablaka ofpoblacipablaka ofSolnceof zvezdy | uniq --group=append

Insights
Linux uniq command is useful for those who often work with arrays of text, not being able to read them yourself. It should be noted that not all versions of uniq to work properly, so sometimes the result can vary.
Your questions regarding the use of command and feedback in comments.
 Top Temporary VPS for Testing & Experiments (2026)
Top Temporary VPS for Testing & Experiments (2026)
Need a fast cloud server for a few hours or days? Deploy an isolated testing environment, run your scripts, and destroy it without any monthly commitments. Secure payments via Crypto (USDT) & PayPal supported.
• Exclusive Welcome Bonus: Get an extra 15% on your first balance top-up within 24 hours after registration.
• Best-in-class Storage VDS configurations with huge disk space for heavy data testing.
• High-speed hardware platform with a stable presence in the Netherlands (Europe).